导言:
“21世纪的竞争是数据的竞争,谁掌握数据,谁就掌握未来”。如何将大量看似杂乱无章的数据进行聚合,并发现潜在的规律也变得越来越重要。本文将先说明数据分析的步骤,再通过python完成实例数据的处理、分析最终展示的全过程,让大家了解数据分析的基础知识。
一、数据分析概述
1.1什么是数据分析
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律。现实生活中,数据分析以及运用到各个方面,例如大家在购物的时候,用过你的搜索关键字、收藏、浏览等行为产生的数据,分析你可能想要的东西,并进行相关的推荐。在实际的工作中,我们通过数据分析的结果来决策未来的方向,而非拍脑袋拍板,避免了损失也提高了工作效率。
1.2数据分析的划分
数据分析的数据分析划分为描述性统计分析、探索性数据分析以及验证性数据分析;其中,探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。
1.3数据分析的步骤

-
明确目标
聚焦要分析的数据目标,针对性的数据采集,处理分析,确保整个数据分析过程的有效进行。
2. 数据采集
根据数据分析确定的目标来收集相关的数据,确保后面数据分析的基础材料。
-
数据处理
通过数据收集来的数据是杂乱无章的数据进行整理、加工,保证搜集的数据的质量,对于后期数据的分析非常的重要。
4. 数据分析
经过处理后的数据,就能得到高质量可分析的数据,通过适当的数据分析策略和工具对数据进行研究分析跟实际场景结合,总结出数据潜在的关系。
5. 数据展示
数据展示及可视化,经过分析的数据,如何跟友好的展示出来,且让用户更好的理解。但是此部分只是辅助,分析出有价值的数据才是重心。
1.4数据分析方法(此处介绍3种常用的易于理解的数据分析方法)
1.漏斗分析法
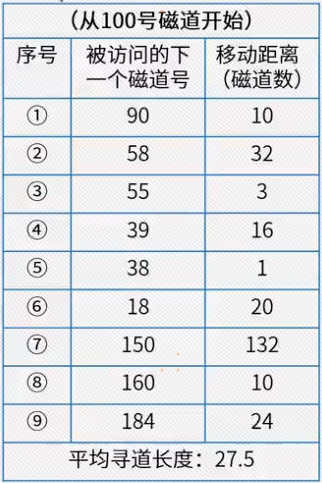
漏斗模型是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况,是一种重要的分析模型。漏斗分析法广泛在互联网行业应用,下图举例银行信用卡申请流程及应用的漏斗模型。
2.对比分析法
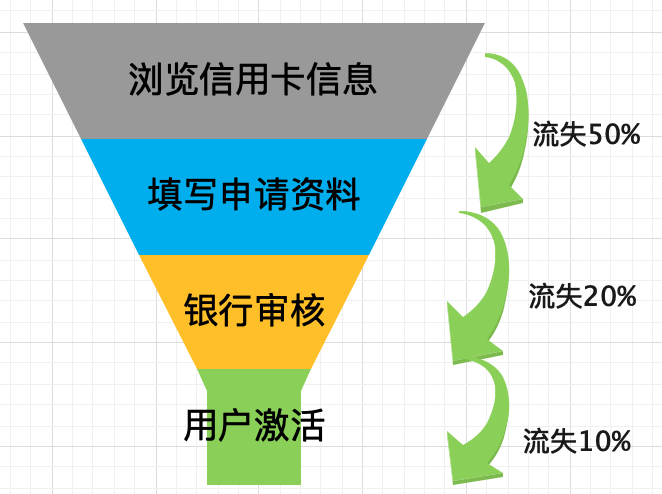
对比分析法又称对比法,通过比较指标的实际数跟基数比较,反应事物数量上的变化。对比法特点是简单、直观、量化。例如我们常见到的环比值=(本周期-上年同周期)/上年同周期 算出环比值。下图为全球主要经济体GDP占世界的比重(%)
图片来源:中国银行在北京发布《2021年度经济金融展望报告》
3.分组分析法
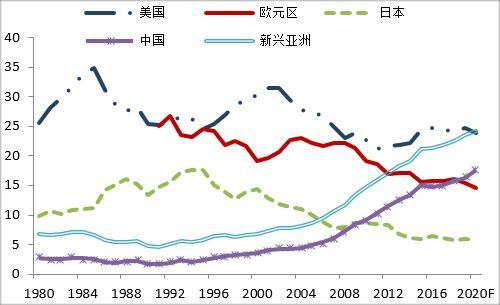
根据实物的内在特性,按照一定的指标,将数据总体划分成不同的部分,分析其内部结构和相互关系,从而了解实物的规律。在使用过程中,分组分析法一般与对比分析法结合使用。例如对于历年来农民工年龄的分布图:
图片来源:国家统计局《2020年农民工监测调查报告》
二、Python中的常用的数据分析库
1.基础库Numpy
python中跟数据分析相关的基础库Numpy,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
2.分析结构化数据的工具 Pandas
Pandas是基于Numpy的一个分析结构化数据工具,支持SQL和表格的数据处理,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
2.1安装Pandas:
pip3 install pandas
2.2 Pandas 基本数据结构:series 跟 dataframe 两种基本数据结构类型,前者类似于一维数组,后者则相当于一张二维数据组。
2.3 Pandas常用操作:
2.3.1创建series 两种方式如下:
#通过数组创建t = pd.Series([1,2,3,4,43],index=list('asdfg'))print(t)#通过字典创建temp_dict = {'a':1,'b':2,'c':3}t2 = pd.Series(temp_dict)print(t2)运行结果:
a 1s 2d 3f 4g 43dtype: int64
a 1b 2c 3dtype: int642.3.2创建 dataframe的方式如下:
temp_dict = {'name':['putao','xigua'],'kg':[1,23],'large':['small','big']}t1 = pd.DataFrame(temp_dict)print(t1)运行结果:
name kg large0 putao 1 small1 xigua 23 big3.数据可视化的绘图库Matplotlib
数据可视化展示工具,python中使用比较多的就是Matplotlib库,可绘制各种图形展示出来。利用Numpy+Matplotlib实例画一个简单的图:
import numpy as npimport matplotlib.pyplot as mt
data = np.random.randn(1000) #要展示的数据基数,此方法可返回正态分布mt.subplot(2,2,4)#生成一个2*2个子区域的画板,4代表在第四个画板区域画图mt.hist(data,facecolor="blue", edgecolor="black", alpha=0.7)#在画板上绘制直方图mt.xlabel("区间") # 显示横轴标签mt.ylabel("数量") # 显示纵轴标签mt.title("分布") # 显示图标题mt.show() #把图展示出来方法上述代码运行结果如下:
三、Python进行数据分析实例
1. 对csv 文件进行读取,写入并对数据进行简单处理的基本操作:
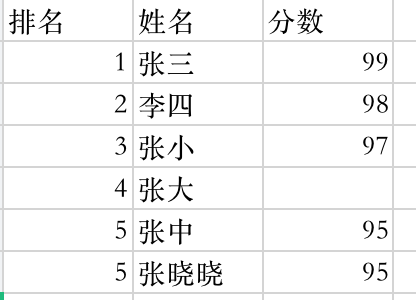
基础csv数据如图:
代码处理过程如下:
import pandas as pdimport csv
old_path = '/Users/zn/Documents/work/data.csv'#数据转换成DataFrame格式df = pd.read_csv(old_path)print(df.head(5))#打印出不同列的数据类型print('datatype of column 姓名 is: ' + str(df['姓名'].dtypes))print('datatype of column 分数 is: ' + str(df['分数'].dtypes))#计算数据之和print('第一名跟第三名分数之和:' + str(df['分数'][0]+df['分数'][2]))运行结果如下:
排名 姓名 分数0 1 张三 99.01 2 李四 98.02 3 张小 97.03 4 张大 NaN4 5 张中 95.0datatype of column 姓名 is: objectdatatype of column 分数 is: float64第一名跟第三名分数之和:196.0Process finished with exit code 0运行结果可以看出,未空的会自动用占位符 ‘NaN'填补。Pandas还可以自动推断出每列的数据类型,以便于对数据的处理。
文本数据的存储的实现:
import numpy as npimport pandas as pd
db = pd.DataFrame(np.array([[1,2],[1,3]]),columns=['序列','数量'])db.to_csv('savedata.csv','|')#在此文件同目录下生产一个csv文件运行后,文件内容:
|序列|数量0|1|21|1|32.数据分析案例
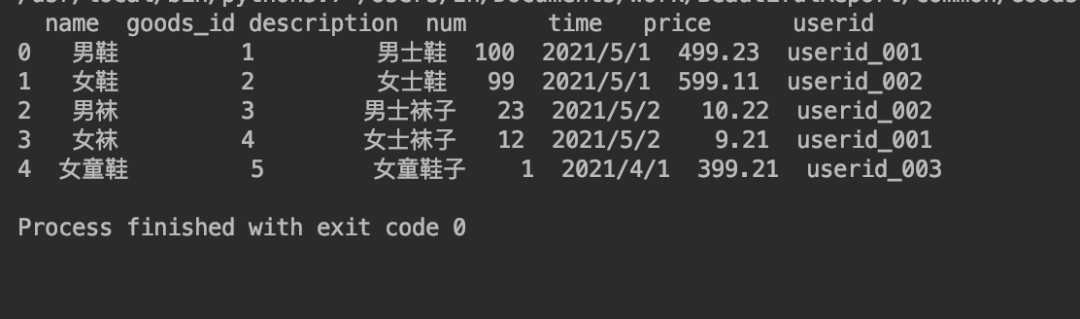
通过上诉的数据分析步骤及python下数据分析的库对上季度本部门测试环境产生的bug进项分析实例。先把数据从bug系统导出后数据放到CSV文件内。文件里的字段信息如下:
-
name:商品名称。
-
goods_id:商品ID。
-
description:商品描述。
-
num:商品销售的数量。
-
time:商品销售时间。
-
price:商品价格。
-
userid:商品购买的用户ID。
整个表格里的数据存在重复、缺失、无用的字段等问题。直接从这些数据里无法看出任何的规律。希望通过以下步骤实现最终的商品价格分布图:
-
去掉重复数据。
-
去掉异常数据,例如负数或者数量为空的数据。
-
找出销量最好的前3名商品。
-
展示商品的价格分布图。
具体实现代码如下:
import pandas as pdimport matplotlib.pyplot as mt
data = pd.read_csv('./goods.csv')# 读取数据data.head()# 去掉没有用的字段例如商品描述data.drop("description", axis=1, inplace=True)data.info
# 查看缺失的数据print('查看用户ID有缺失的数据:\n', data[data['userid'].isnull()])# d对于重点字段填补缺失值data['userid'] = data['userid'].astype("str").fillna("unknow")# 查看重复的数据量,duplicated()方法检测的标准是整行都一样算重复print('统计重复数据的和:\n', data.duplicated().sum())# 删除重复的数据data = data.drop_duplicates()# 获取销量前三的商品,商品ID分组然后按照销量合并算出销量最多的data_thr = data["num"].groupby(data['goods_id']).sum().sort_values(ascending=False)# 获取销量前三的商品print('销量前三的商品:\n', data_thr[:3])# 商品价格分布跟商品价格与销量之间的关系data_stock = data.drop_duplicates(['goods_id'])print('查看处理后的数据:\n',data_stock['price'].describe())#定义商品的价格区间 ,左开右闭price = pd.cut(data_stock['price'],bins=[5,10,20,50,100,500,1000,5000,10000]).value_counts().sort_index()mt.figure(figsize=(6,3))#设置画布的长宽不是cm是英尺price.plot(kind='bar')#bar标示我们画的是个柱状图mt.savefig('./test.png')mt.title('商品价格跟销售数量图')mt.xticks(fontsize =4,rotation=30)mt.xlabel('价格(元)',fontsize=8)mt.ylabel('销售数量',fontsize=8)mt.show()运行结果:
查看用户ID有缺失的数据:name goods_id num time price userid13 玩具3 13 2 NaN 12.34 NaN14 玩具4 14 3 NaN 22.00 NaN
统计重复数据的和:2销量前三的商品:goods_id12 1761 1002 99Name: num, dtype: int64查看处理后的数据:count 20.000000mean 616.822000std 2217.183709min -12.30000025% 7.40750050% 14.33000075% 321.280000max 10000.000000Name: price, dtype: float64运行后的分析图如下:
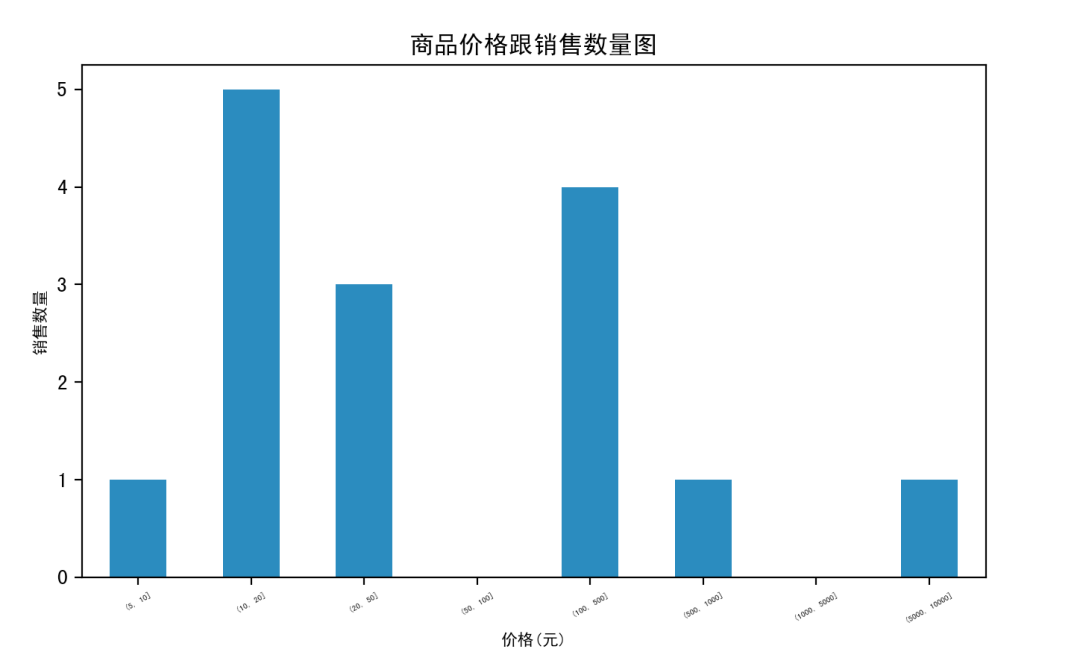
pandas.describe()函数的用法:从上面结果可以看出来,对于数值型数据输出结果指标包括count,mean,std,min,max以及第25百分位,中位数(第50百分位)和第75百分位。对于不同类型的,输出的指标不一样,感兴趣的实验下对于对象类型数据和混合数据类型DataFrame输出的指标。
总结
上文中阐述了数据分析的步骤,并通过具体实例,对数据的整理、清洗、汇总、分析、最后把数据展示出来。文中用到的方法,还有很多其他参数可增加会产生不同的效果图及对比值,感兴趣的同学,可以尝试使用